在数千条历史记录中找到已经忘记标题的网页,你可以试试 Memex

每天,我们都会用浏览器访问无数网页,从信息流中汲取各方面知识储备,却很少归纳整理。于是,当某一天你突然回想起曾经看到过什么内容时,用尽一切办法,也很难翻到当初的那个页面了。
而这,正是 WorldBrain’s Memex(以下简称 Memex)想要解决的问题。
快速全面的正文索引
我们知道,无论是 PDF 还是 Office 文档等,都支持全文搜索;但到了网页浏览器上,却只能搜索历史记录的标题或链接。碰上微博和 Twitter 这种时间线刷一遍标题都不改的网页,更是两眼一黑。
而 Memex 对此的解决方案也很简单:在后台为所有你访问过的网页建立正文索引,储存至本地数据库,并在搜索时展现匹配结果。
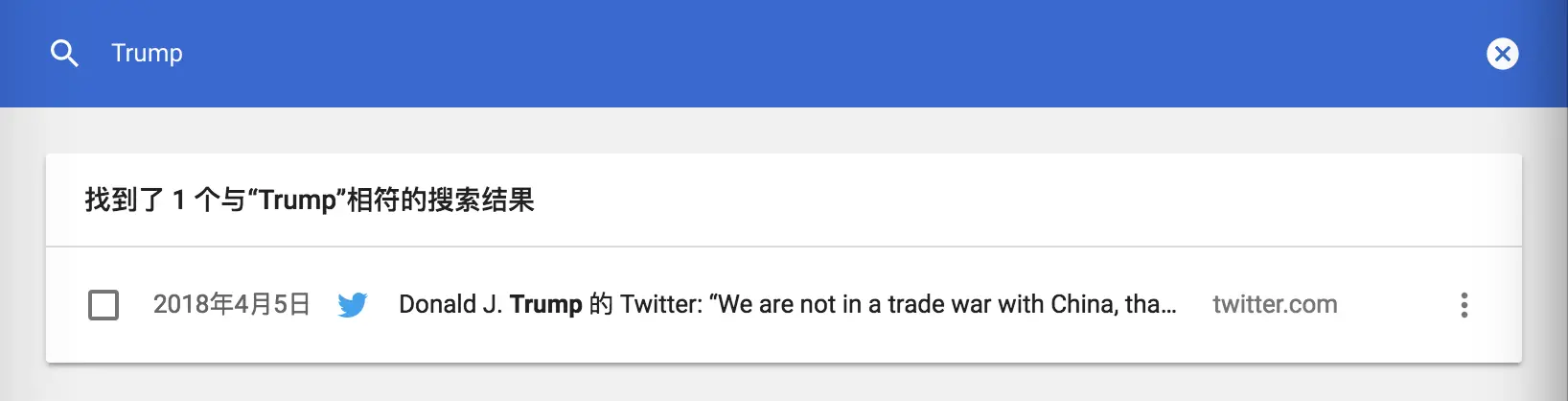
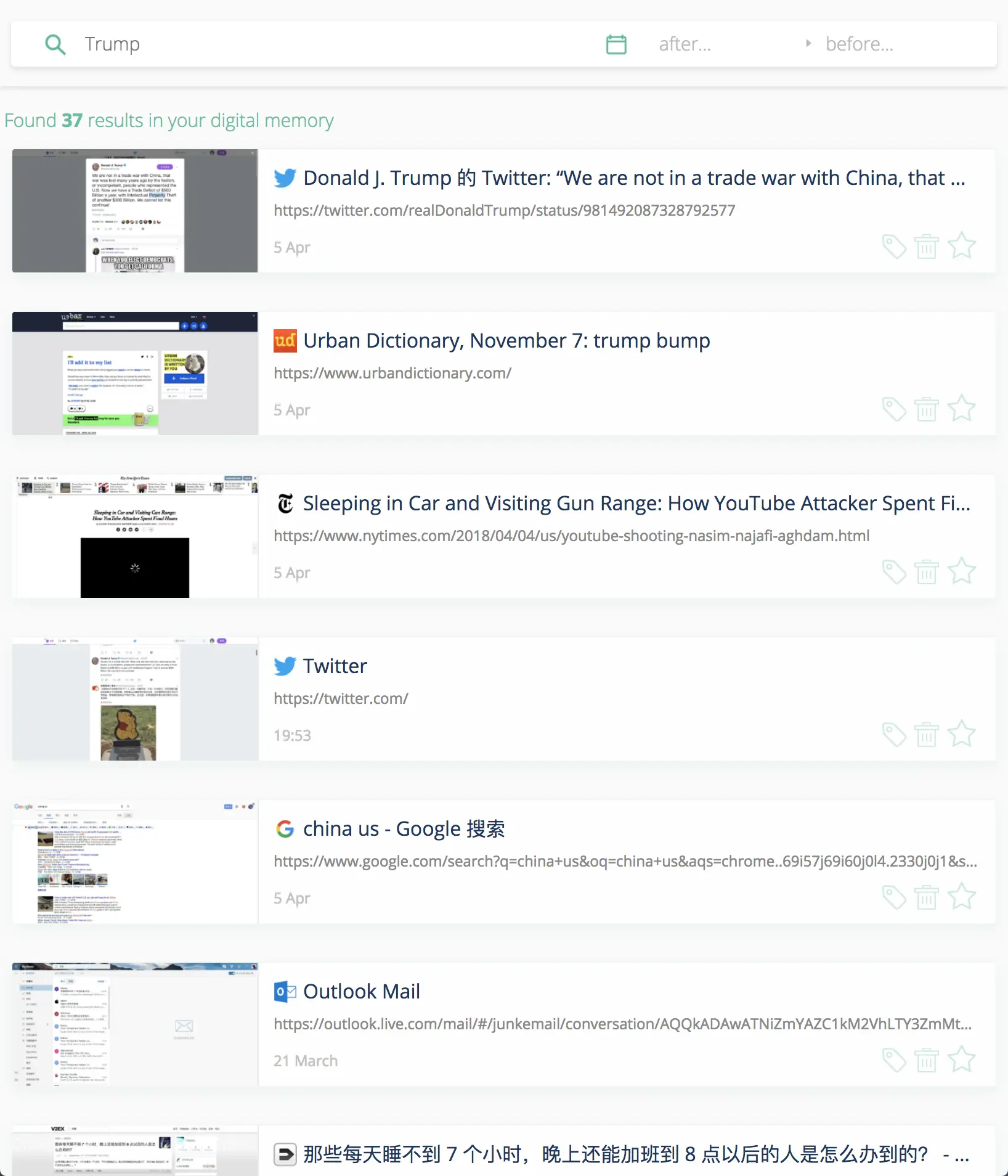
以川皇为例,使用 Chrome 原生历史记录搜索功能时,我们只能找到一条孤零零的 tweet;而使用 Memex 时,还能同时找到三十余个正文提到 Trump 的网页,并配合页面预览,帮助你快速拾起回忆。
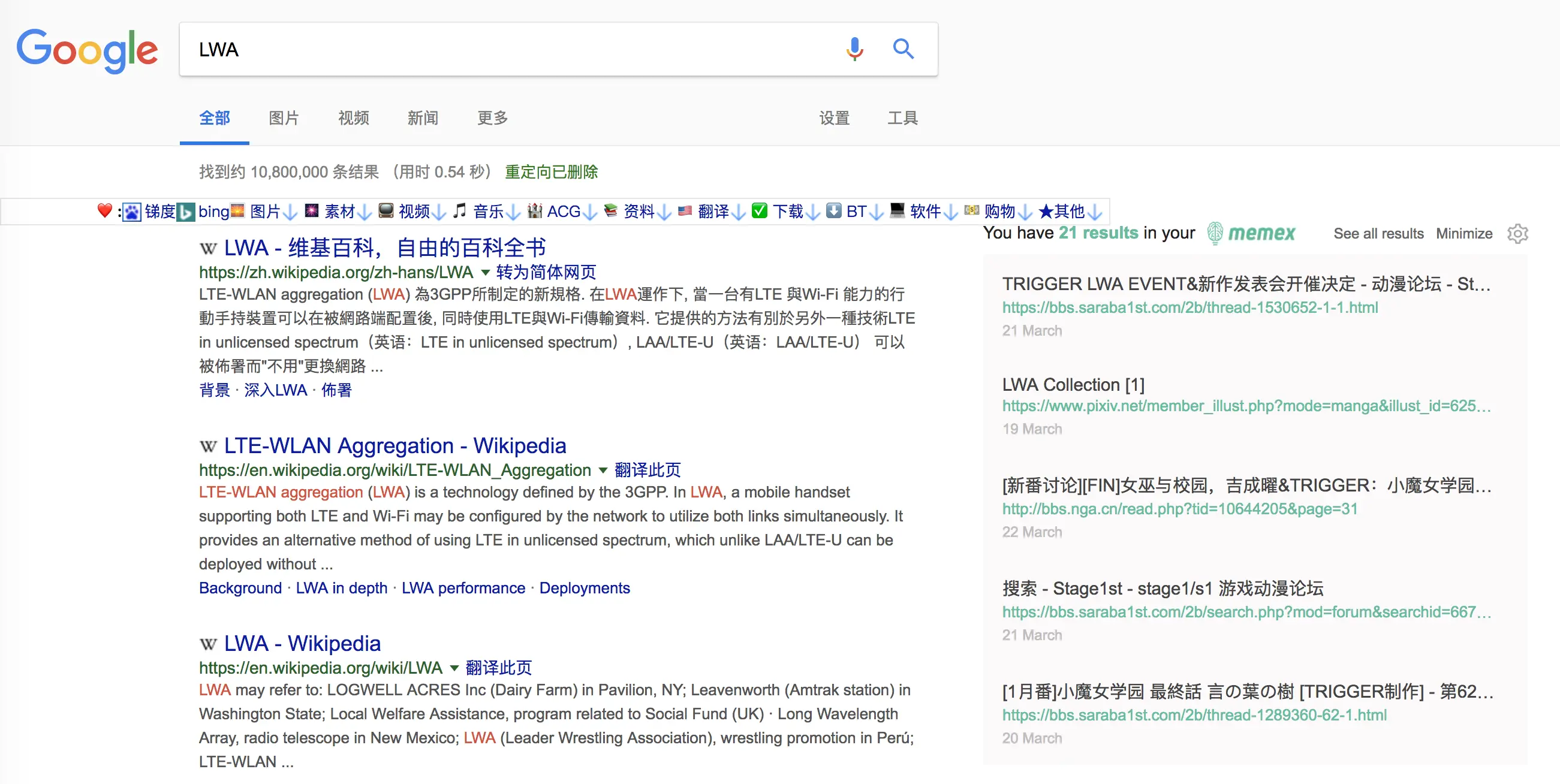
此外,Memex 还可以在 Google 搜索结果页面右侧展示相关浏览记录,在一处聚合查看。
由于大部分索引内容都是文本形式,Memex 数据库所占用的空间也仅有数十 MB 而已,不会对浏览器的性能造成太大影响。
用自然语言进行搜索
安装 Memex 后,它就会勤勤恳恳地开始幕后工作。当你需要用到时,只要在地址栏敲击 W + 空格键,再输入要搜索的结果,Memex 就会智能建议你可能需要的内容。再次回车后,你便来到了全部搜索结果页面。
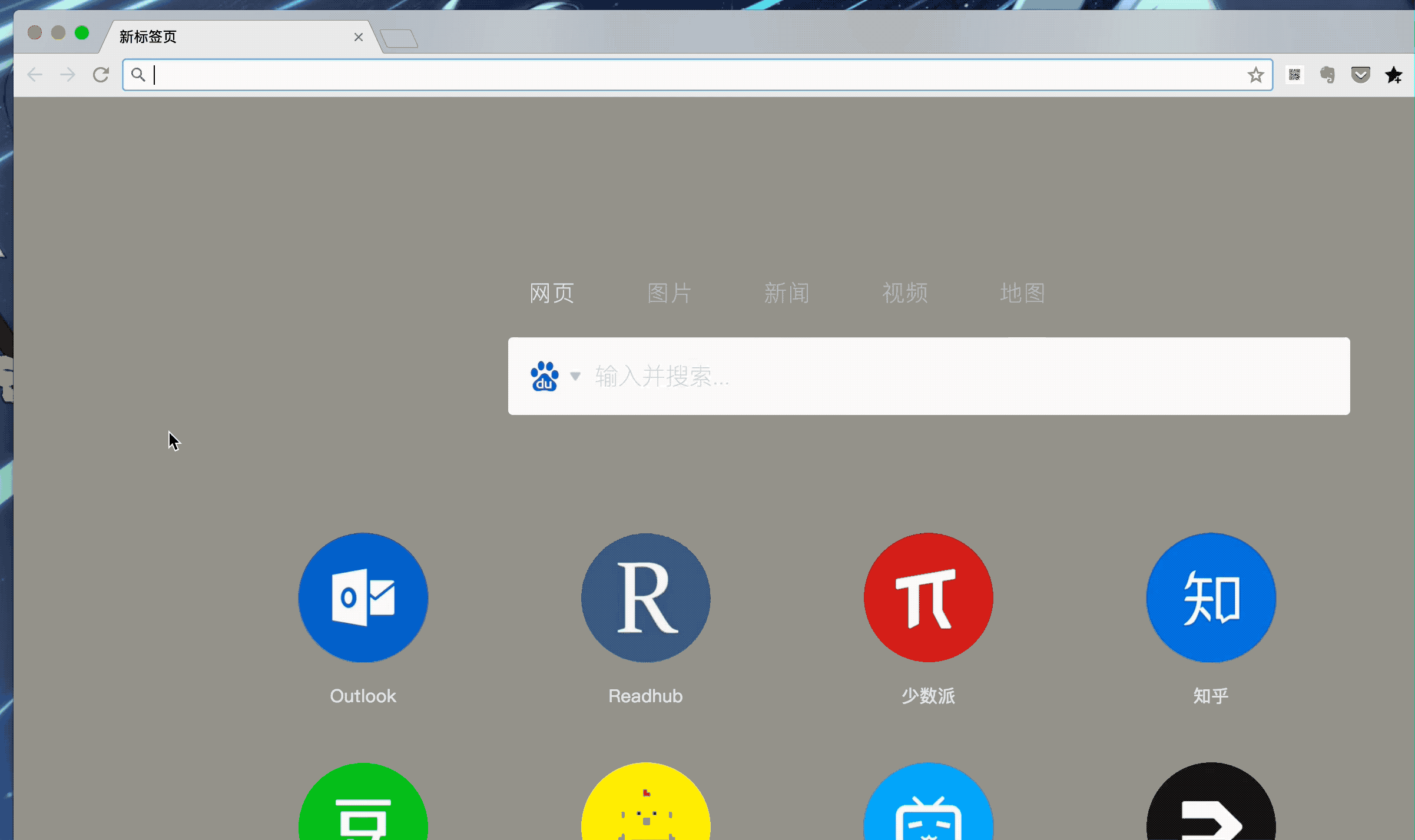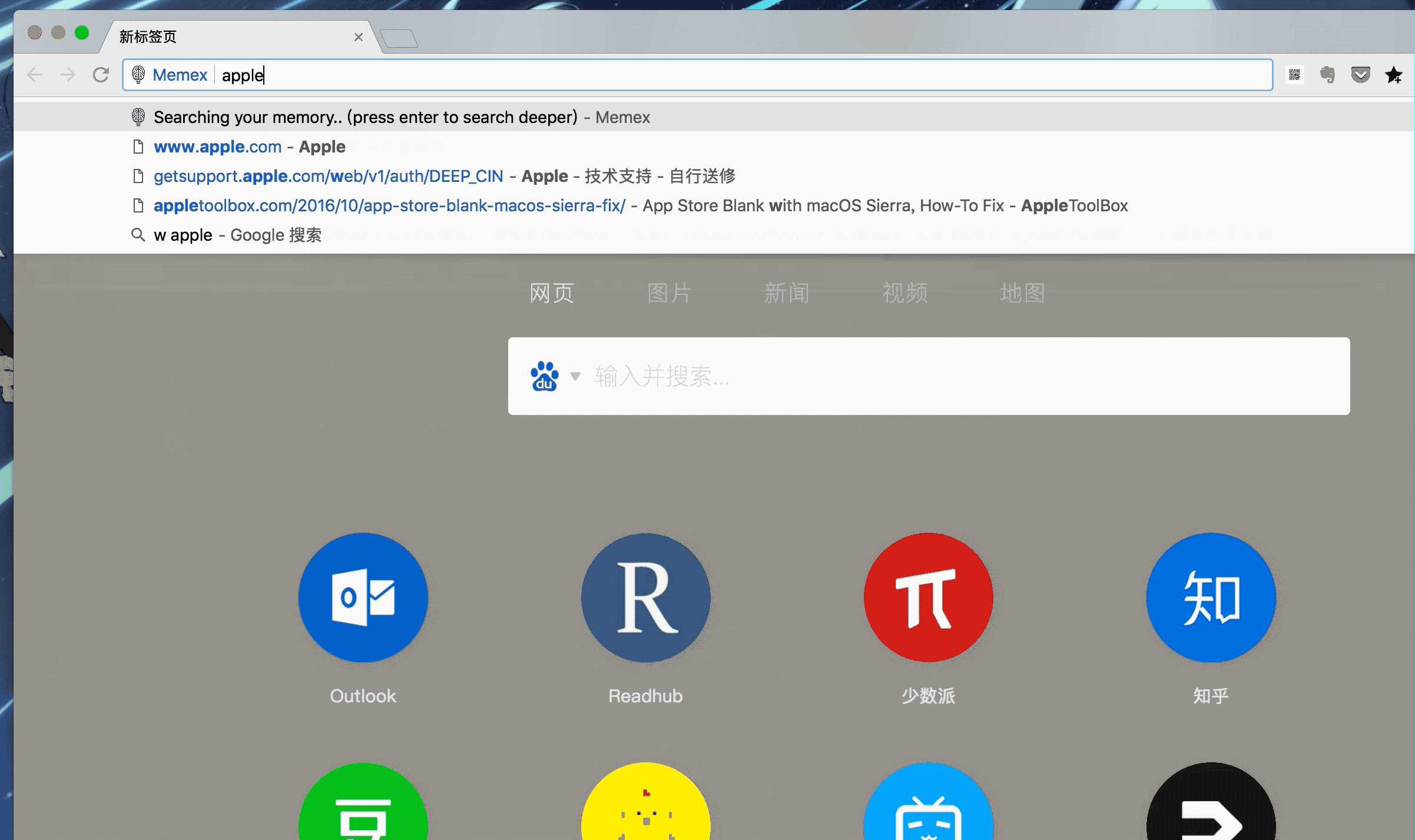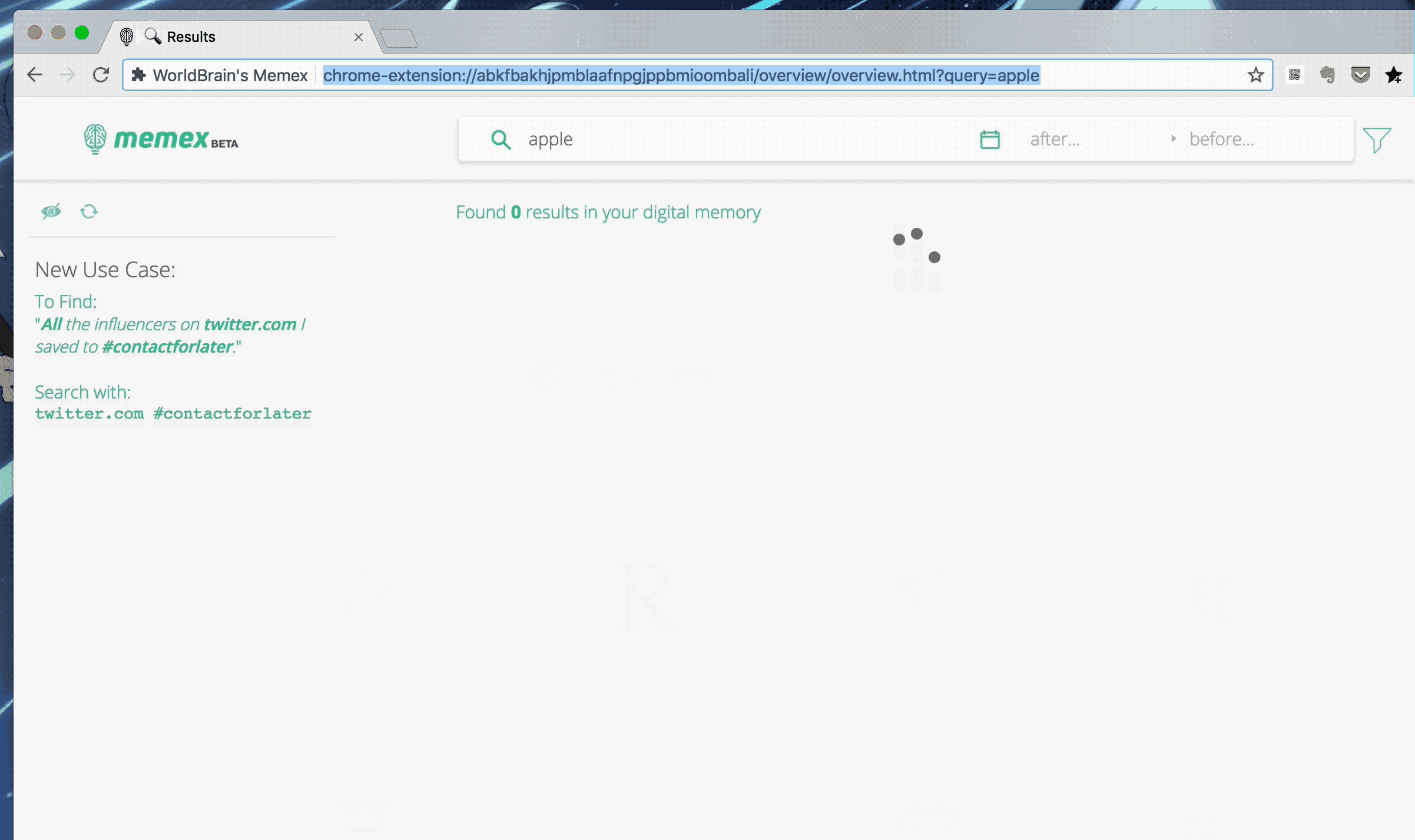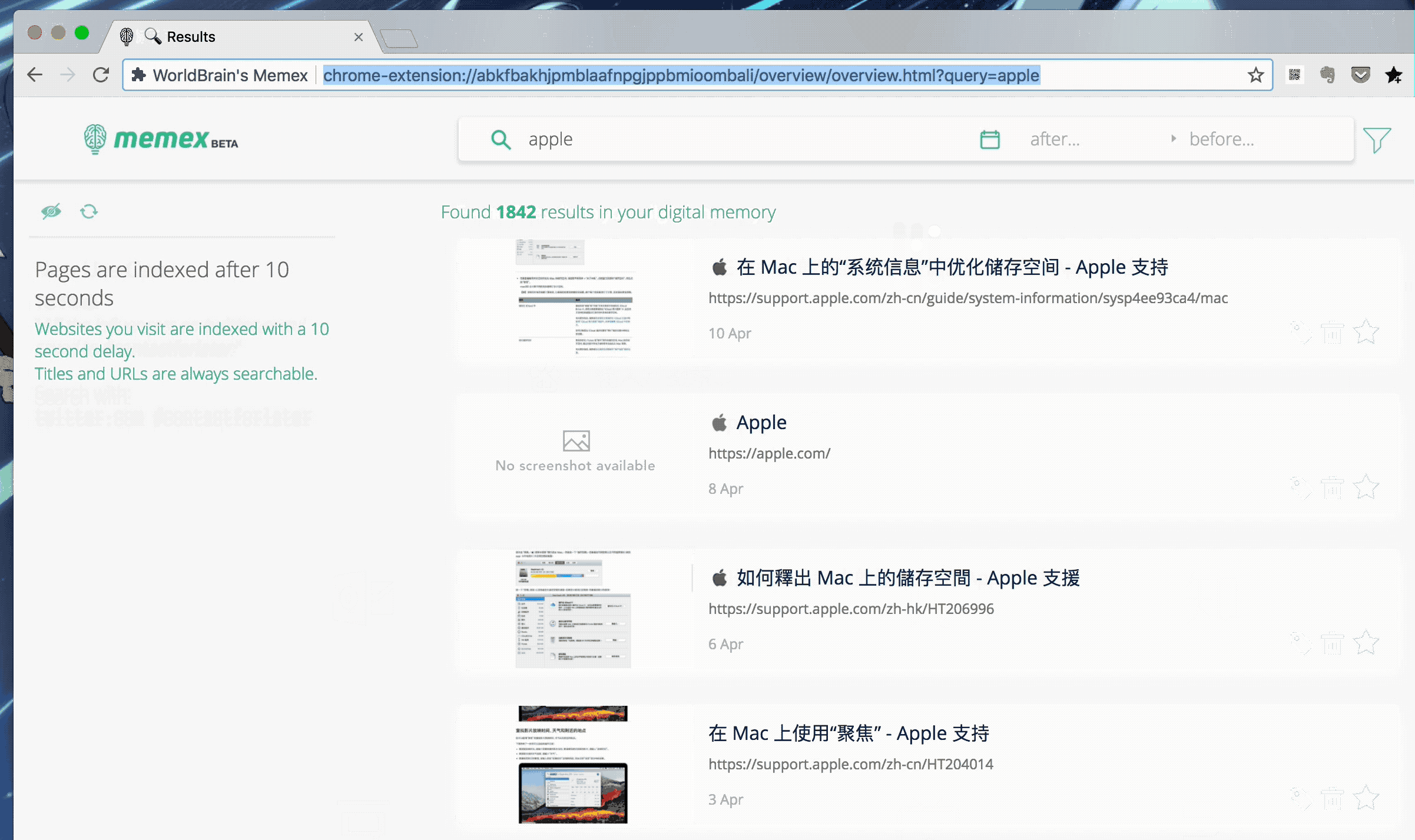
除了简单的语义匹配外,Memex 还支持更高级的搜索语法,例如 before/after:"date" 可以指定日期范围,domain.com 则可以限定检索网页。

如果你觉得记住上面的语法有点难度,不妨试试直接用自然语言描述。例如,the tab I closed last year on github.com about fuck 就能准确定位我去年在 GitHub 上浏览到的有关 fuck 的内容。

强大的内容过滤器
如果你更偏爱鼠标操作,也可以用图形操作界面中的选项更直观的过滤内容。在 Memex 的搜索页面,你可以用 before、after 限定日期范围。点击漏斗图标,还会出现 Tags、Domains 、Misc 等进阶选项,进一步缩小范围。
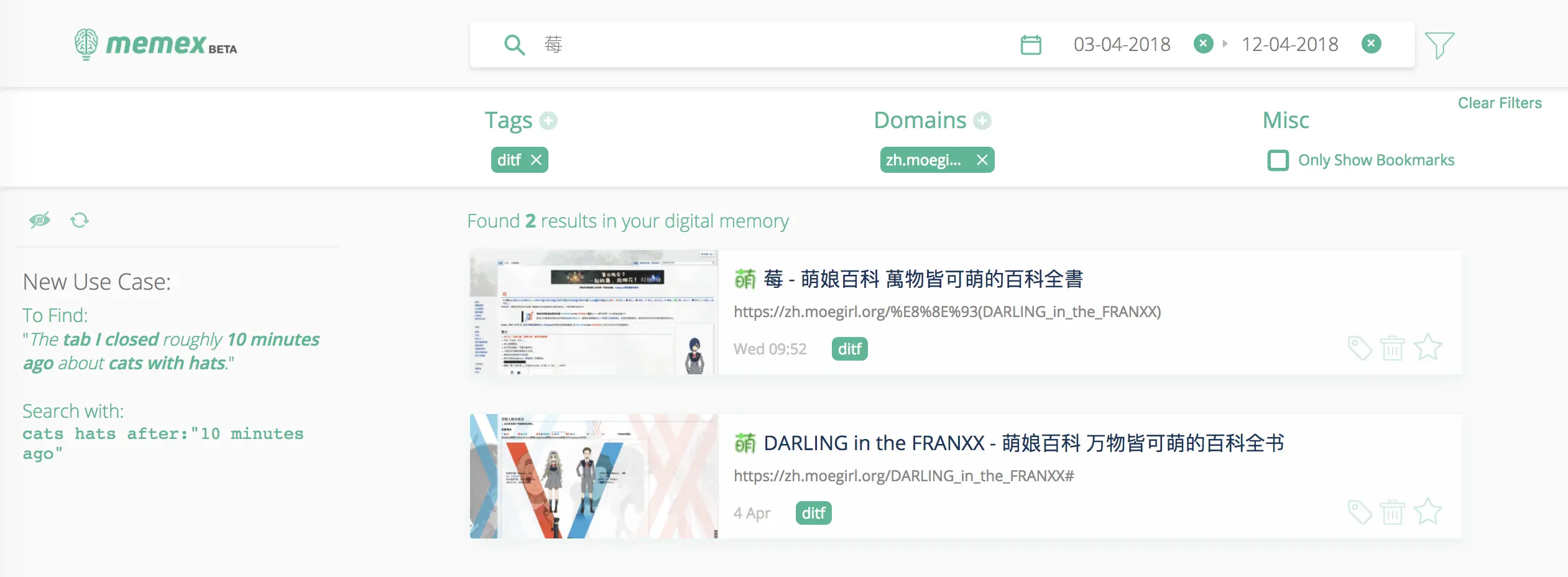
在历史记录或 Memex 选单中,你还可以为页面添加特定标签,也就是上文中的 Tags 过滤器。以后只要输入 #标签名称,就能随时定位了。
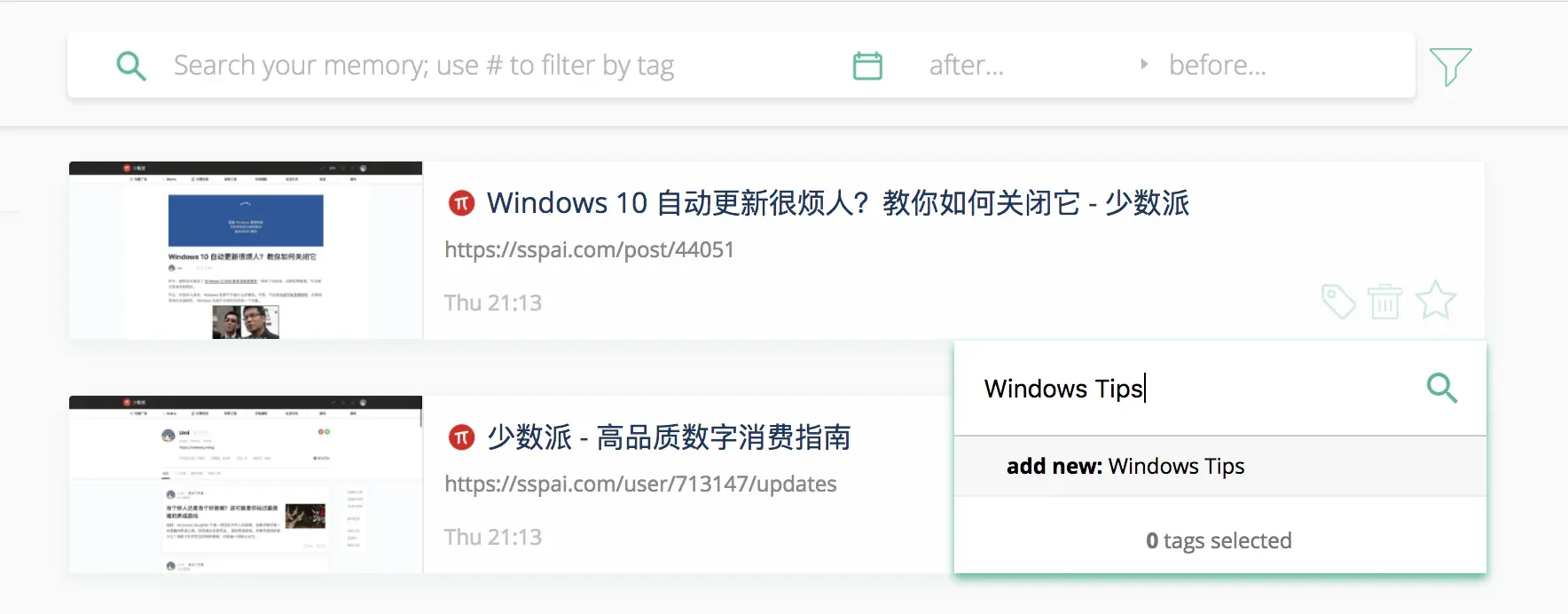
更多贴心细节
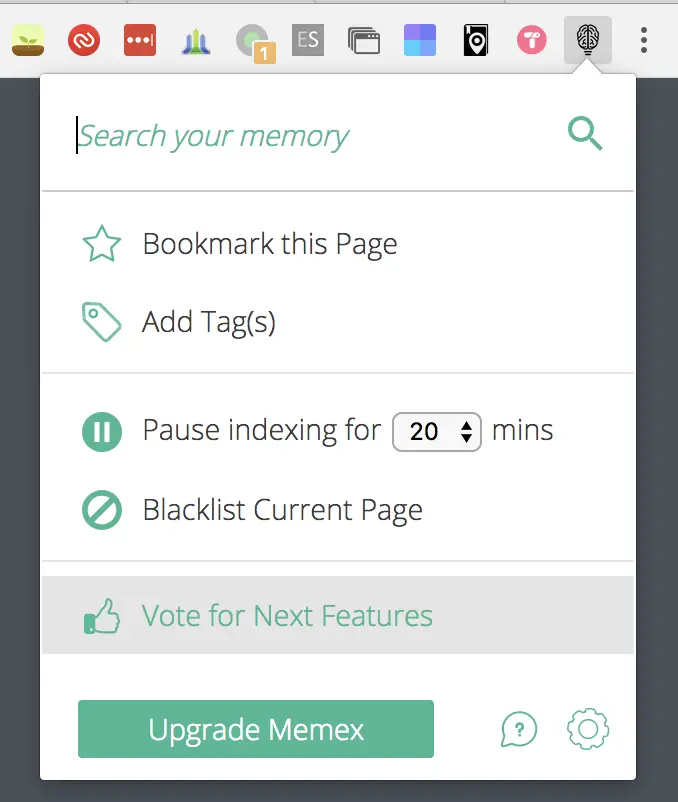
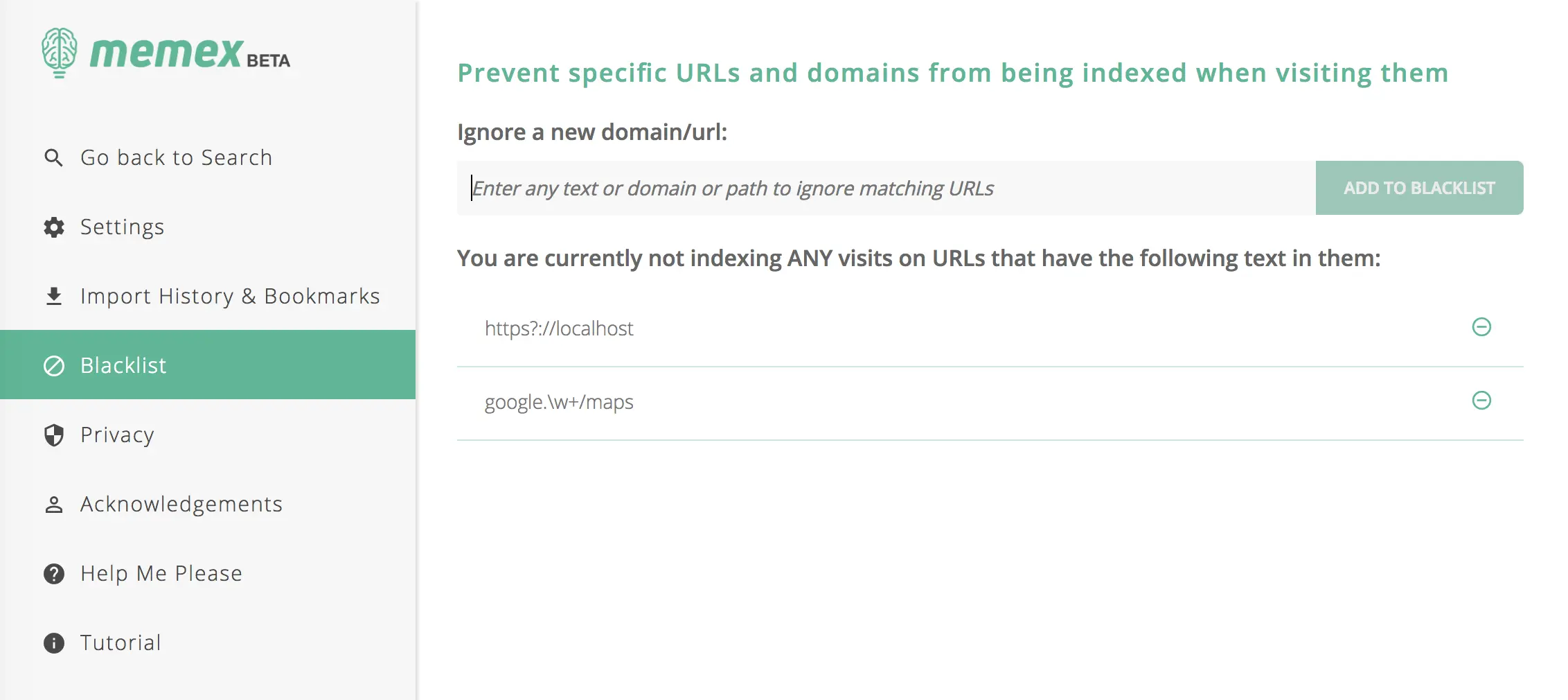
访问记录里有见不得人的网站?你只需要点击工具栏上 Memex 的图标,或者进入设置界面,将其加入黑名单即可。如果你要长时间进行地下工作,也可以设置在一段时间内暂停索引。
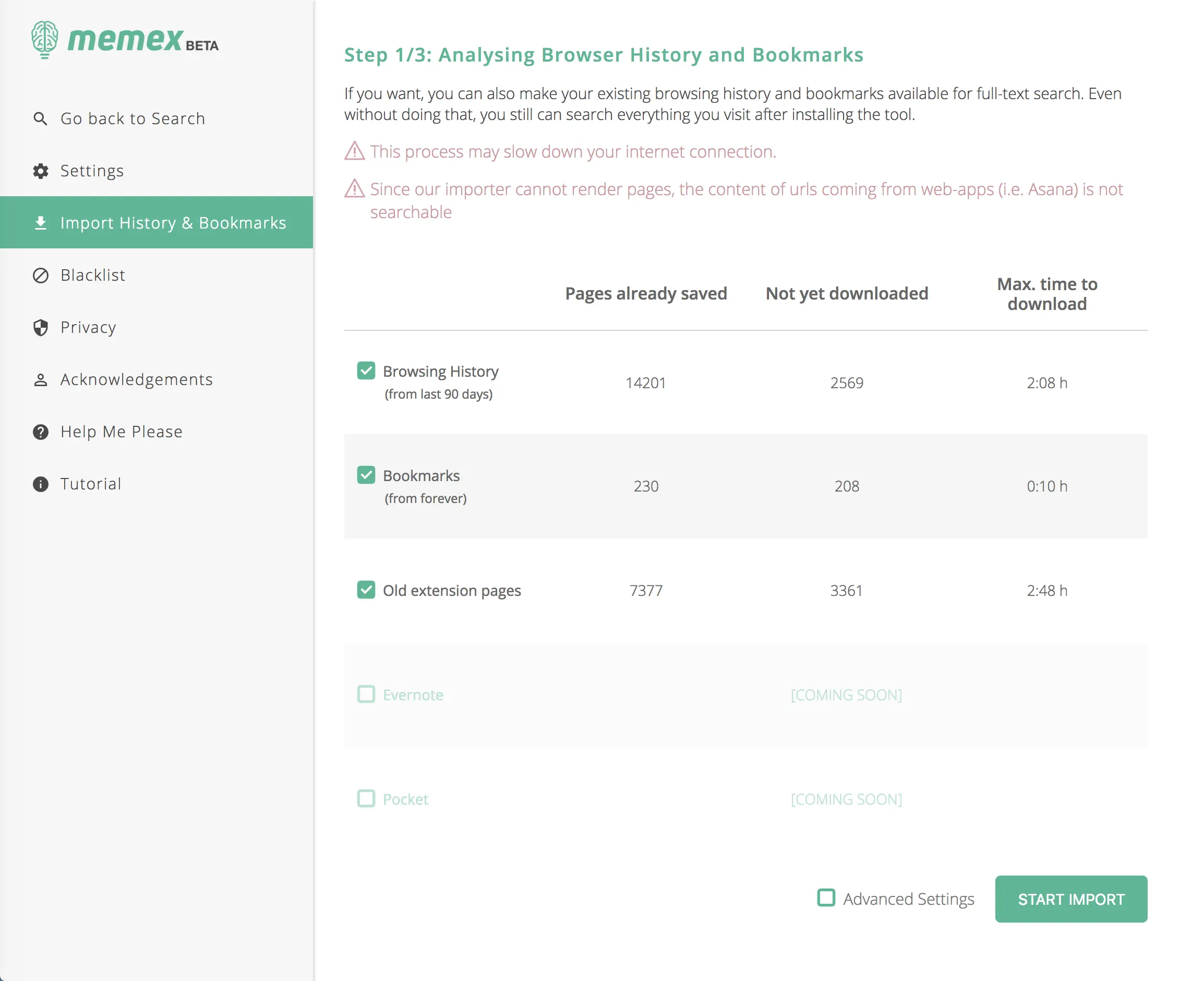
在 Memex 的设置中,你还可以导入之前的书签和历史记录,不再遗漏半点信息。
目前,你可以在 Chrome Web Store 和 Firefox Add-ons 免费下载 WorldBrain’s Memex。扩展目前免费,云同步等正在开发的高级功能会在未来以 订阅模式收费。